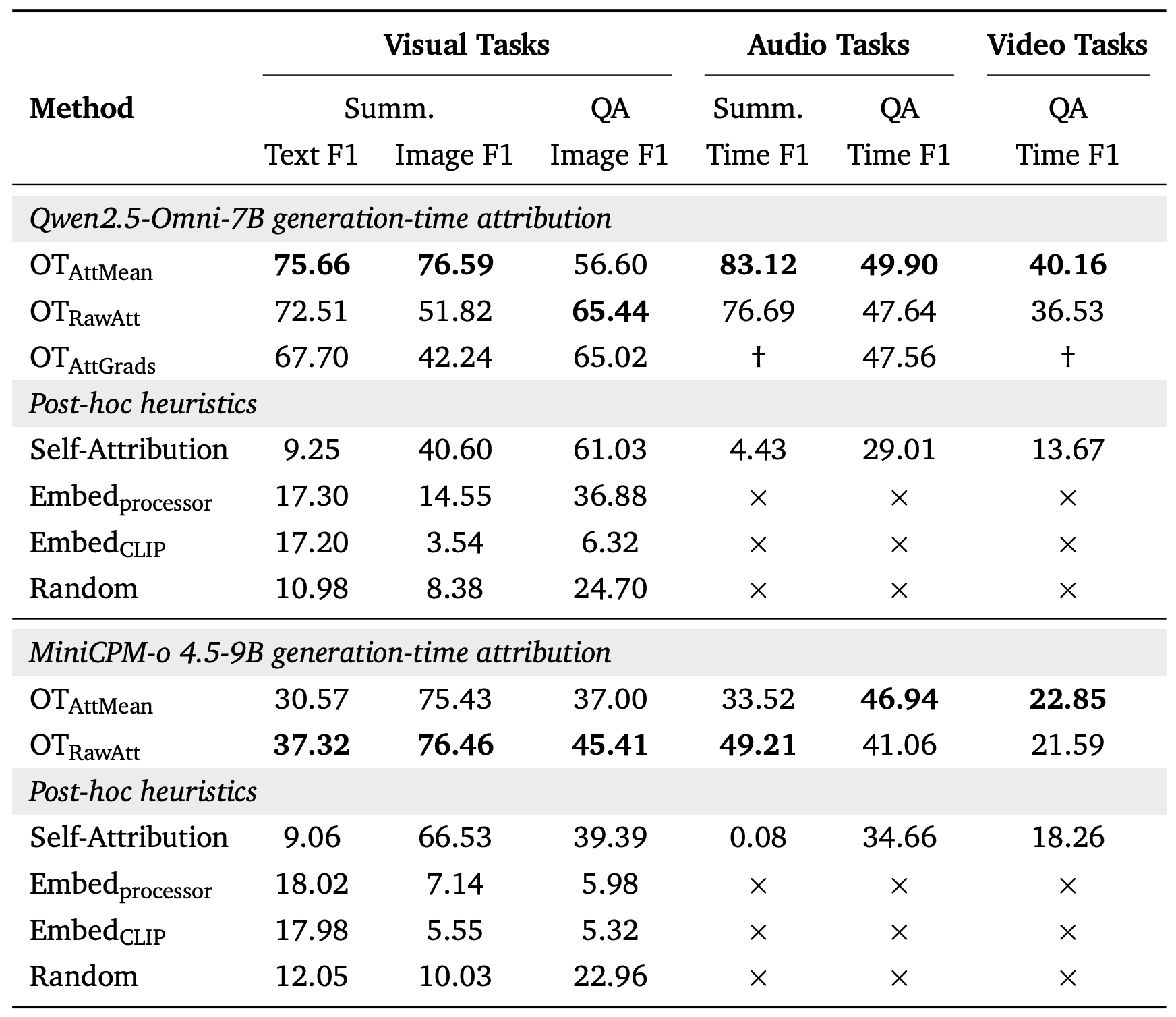
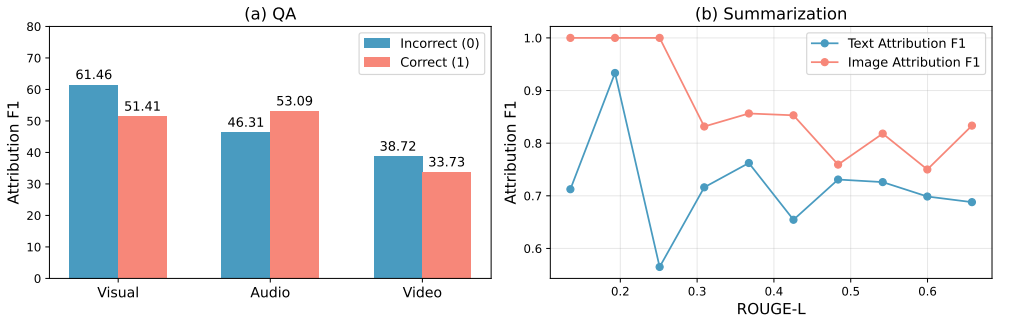
- Visual QA: Mantis-eval
- Visual summarization: MMDialog, CliConSummation
- Audio QA: MMAU
- Audio summarization: MISP
- Video QA: Video-MME
OmniTrace
A Unified Framework for Generation-Time Attribution in Omni-Modal LLMs
1University of California, Santa Barbara
2eBay
2eBay
Generation-time tracing
Omni-modal
Model-agnostic
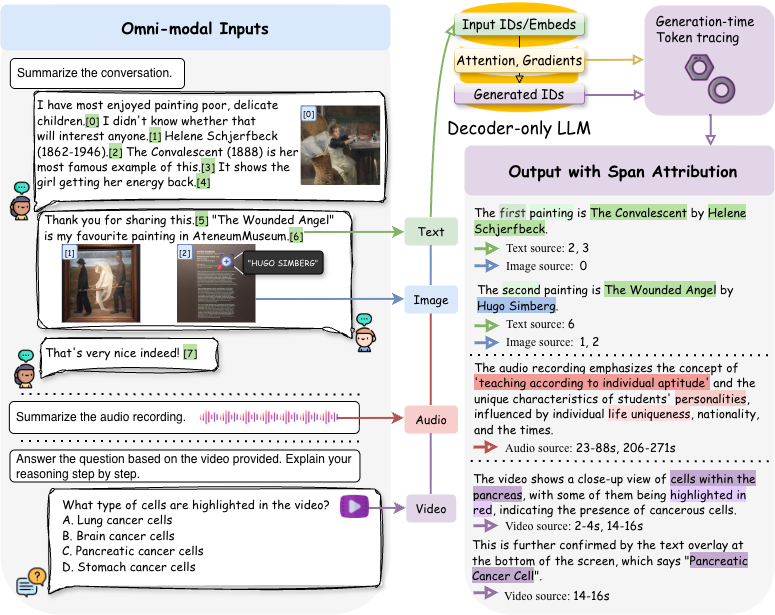
OmniTrace traces each generated token to candidate source tokens across text, image, audio, and video, then aggregates them into span-level source explanations.